Adding Variable Transformers
Project Hadron provides a library of transformers, which may clean, reduce, expand or generate feature representations. Machine learning models have very specific ingestion needs such as numeric only non-null data, normalised looking distributions and optimised features of interest, without which the model will produce poor results.
The main agenda for a model to be accurate and precise in predictions, is that the algorithm should be able to easily interpret the data’s features. The majority of the real-world datasets for machine learning are highly susceptible to be sparce, inconsistent, and noisy due to their heterogeneous origin, while models have high expectations of the format, veracity, size and quality of the data they ingest.
Data transformation is a required first step before any machine learning model can be applied, because the algorithms learn from the data and the learning outcome for problem solving heavily depends on the proper data needed to solve a particular problem. Data transformation is an integral step in Machine Learning as the quality of data and the useful information that can be derived from it directly affects the ability of a model to learn.
from ds_discovery import Wrangle, SyntheticBuilder, Transition
import numpy as np
import pandas as pd
Components Used
# in-memory instances
builder = SyntheticBuilder.from_memory()
tr = Transition.from_memory()
wr = Wrangle.from_memory()
Dimensionality Reduction
Dimensionality reduction is a machine learning or statistical technique of reducing the features of a given dataset in a problem by obtaining a set of principal features of relevance whose representation retains some meaningful properties of the original dataset.
sample_size = 1000
df = pd.DataFrame(index=range(sample_size))
df['nulls'] = [np.nan] * sample_size
df['ones'] = builder.tools.get_number(1, 2, size=sample_size)
df['more_ones'] = df['ones']
df['zeroes'] = builder.tools.get_number(0, 1, size=sample_size)
df['cats'] = builder.tools.get_category(selection=['A','B'], size=sample_size)
df['nums'] = builder.tools.get_number(100, size=sample_size)
df['more_nums'] = builder.tools.correlate_values(df, header='nums', jitter=0.3)
df.columns.to_list()
['nulls', 'ones', 'more_ones', 'zeroes', 'cats', 'nums', 'more_nums']
Feature selection
Feature selection is the process of selecting a subset of relevant features or variables, reducing the dimensionality of the dataset. There are three strategies for future selection, filter methods, wrapper methods, and embedded methods. Preprocessing predominantly tends to use filter methods which rely on the characteristics of the data. These tend to not use machine learning algorithms and are thus model agnostic giving them more scope as a pre-processing tool. Finally they are less computationally expensive and though they give a lower prediction performance they are suited for quick removal of irrelevant features.
Wrapper methods are not commonly used as they are computationally very expensive. Embedded methods are found closer to the model and tend to perform feature selection as part of the model’s construction process.
df = tr.tools.auto_drop_duplicates(df)
# 'ones' column has been dropped
df.columns.to_list()
['nulls', 'more_ones', 'zeroes', 'cats', 'nums', 'more_nums']
df = tr.tools.auto_drop_columns(df)
# 'zeros' and 'nulls' columns have been dropped
df.columns.to_list()
['cats', 'nums', 'more_nums']
df = tr.tools.auto_drop_correlated(df, threshold=0.8)
# 'nums' column has been dropped
df.columns.to_list()
['cats', 'more_nums']
Feature projection
Feature projection transforms the data from the high-dimensional space to a space of fewer dimensions. To achieve this transformation we use principal component analysis (PCA). PCA, is a dimensionality-reduction method that transforms a large set of features into a more manageable smaller set that still contain most of the information in the large set.
We start with a dimensionality of 1000x22.
df = builder.tools.model_synthetic_classification(sample_size, n_features=20)
df['cats'] = builder.tools.get_category(selection=['A','B'], size=sample_size)
df.shape
(1000, 22)
df = tr.tools.auto_projection(df, headers=['target'], drop=True, n_components=4)
After running our projection we have reduced the dimensionality to
1000x6. We specifically didn’t include target and cats was
excluded as it isn’t numeric.
df.columns.to_list()
['target', 'cats', 'pca_A', 'pca_B', 'pca_C', 'pca_D']
Missing data imputation
Imputation is the act of replacing missing data with statistical estimates of the missing values. The goal of any imputation technique is to produce a complete dataset that can be used to train machine learning models. There are three types of missing data: * Missing Completely at Random (MCAR); where the missing data has nothing to do with another feature(s) * Missing at Random (MAR); where missing data can be interpreted from another feature(s) * Missing not at Random (MNAR); where missing data is not random and can be interpreted from another feature(s)
When choosing a strategy to replace missing data, understanding the type of data that is missing is critical to the approach one takes in replacing it.
sample_size = 100
df = pd.DataFrame(index=range(sample_size))
df['num_nulls'] = builder.tools.get_dist_normal(mean=0, std=1, quantity=.9, size=sample_size, seed=11)
builder.canonical_report(df, stylise=False)

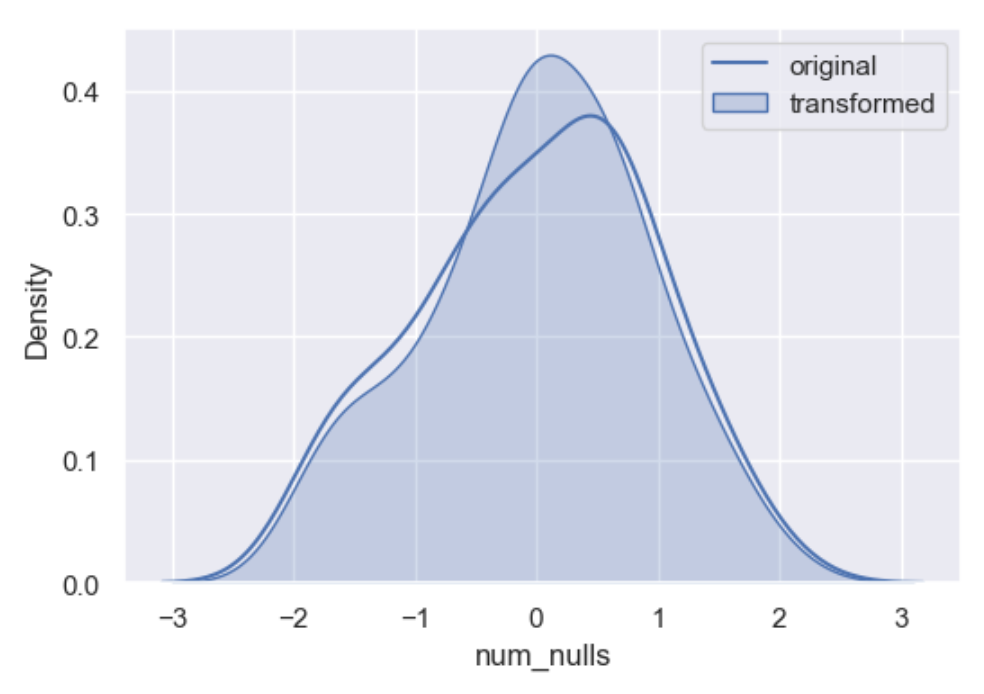
Mean and median imputation is a commonly used technique, consisting of replacing all occurrences of missing values by the mean, if the variable has a Gaussian distribution, or median, if the variable has a skewed distribution. Replacing missing data by the mode is not common practice. As the mean and median methods apply to numeric values only, they are only suitable for continuous and discrete numerical variables.
df['mean'] = wr.tools.correlate_missing(df, header='num_nulls', method='mean', seed=11)
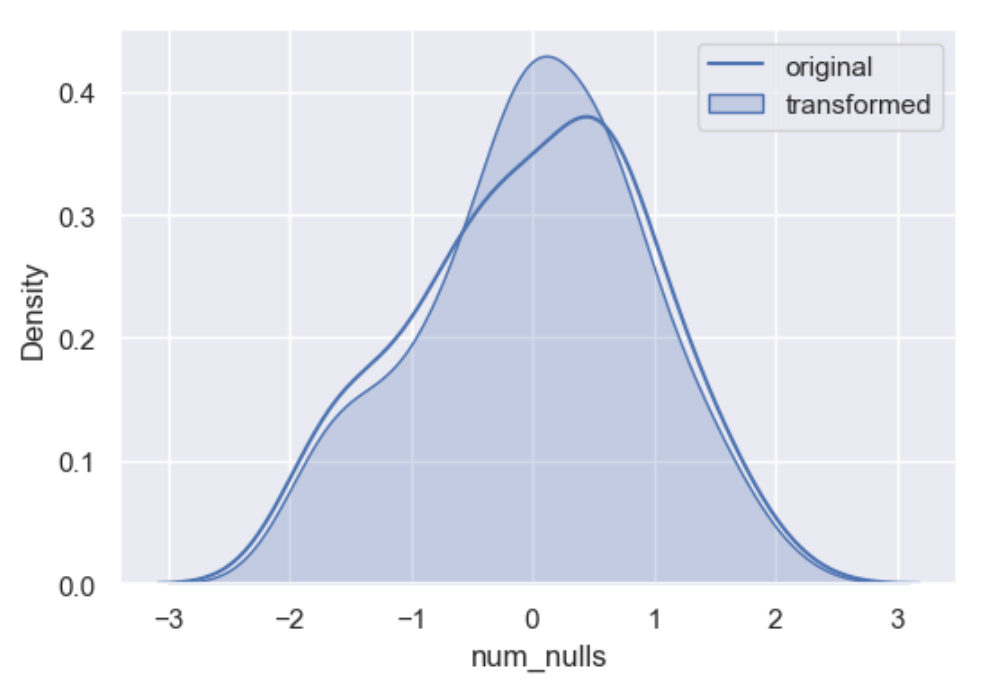
A popular approach to missing data imputation is to use a model to predict the missing values. Although any one among a range of different models can be used to predict the missing values, the k-nearest neighbor (KNN) algorithm has proven to be generally effective. We use it here where a new sample is imputed by finding the samples in the dataset closest to that sample and average nearby points to fill in the value.
df['knn'] = wr.tools.correlate_missing(df, header='num_nulls', method='neighbour', weights='weighted', seed=11)
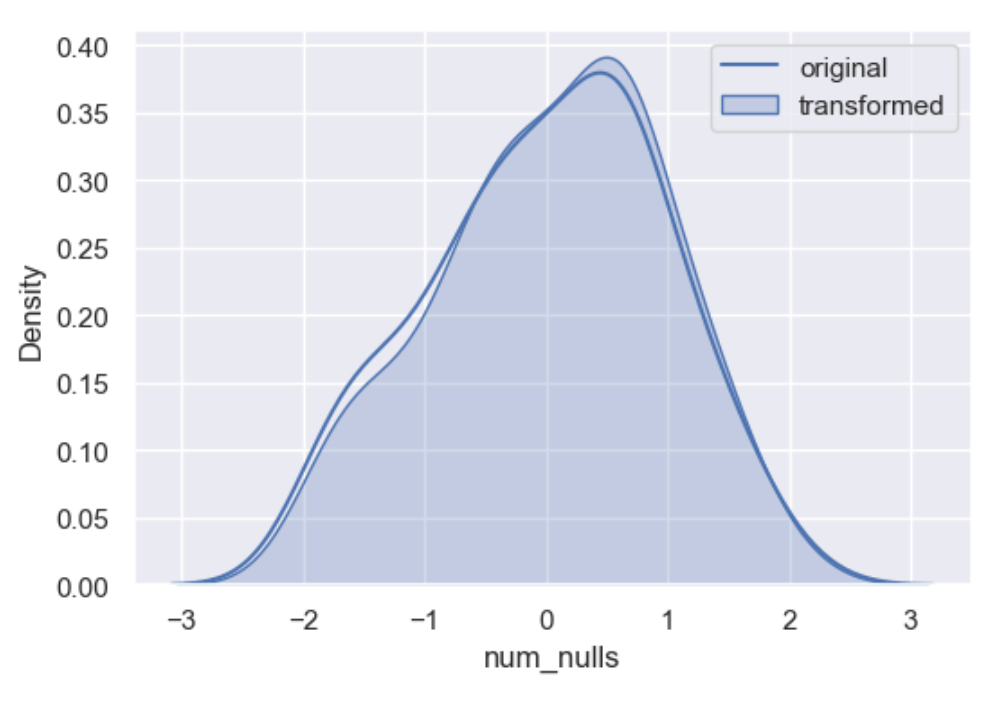
Random sampling imputation is in principle similar to mean, median, and mode imputation in that it considers that missing values should look like those already existing in the distribution. Random sampling consists of taking random observations from the pool of available data and using them to replace the missing data. In random sample imputation, we take as many random observations as missing values exist in the variable.
In both numerical and categorical variables, the distribution of the variable is preserved by sampling observations at random to replace missing data.
df['random'] = wr.tools.correlate_missing(df, header='num_nulls', method='random', seed=11)
One of the metod options is Indicator. Indicator is not an imputation method but an imputation techniques. Imputations such as mean, median and random will affect the variable distribution quite dramatically and is a good idea to flag them with a missing indicator before their imputation to tag values are where real and those that have been modified.
df['indicator'] = wr.tools.correlate_missing(df, header='num_nulls', method='indicator')
Resulting with a flag in each row there is a null.
0 90
1 10
Name: indicator, dtype: int64
Categorical encoding
Categorical encoding is a process where we transform categorical data into representative numerical data. It is a critical step in data pre-processing where most models expect numerical input.
sample_size = 100
df = pd.DataFrame(index=range(sample_size))
df['gender'] = builder.tools.get_category(selection=['M','F','U'], relative_freq=[6,4,1], size=sample_size, seed=11)
df['code'] = builder.tools.get_category(selection=['90674', '90682', '90686', '90688', '90694', '90756'], relative_freq=[13, 9, 7, 4, 2, 1], size=sample_size, seed=11)
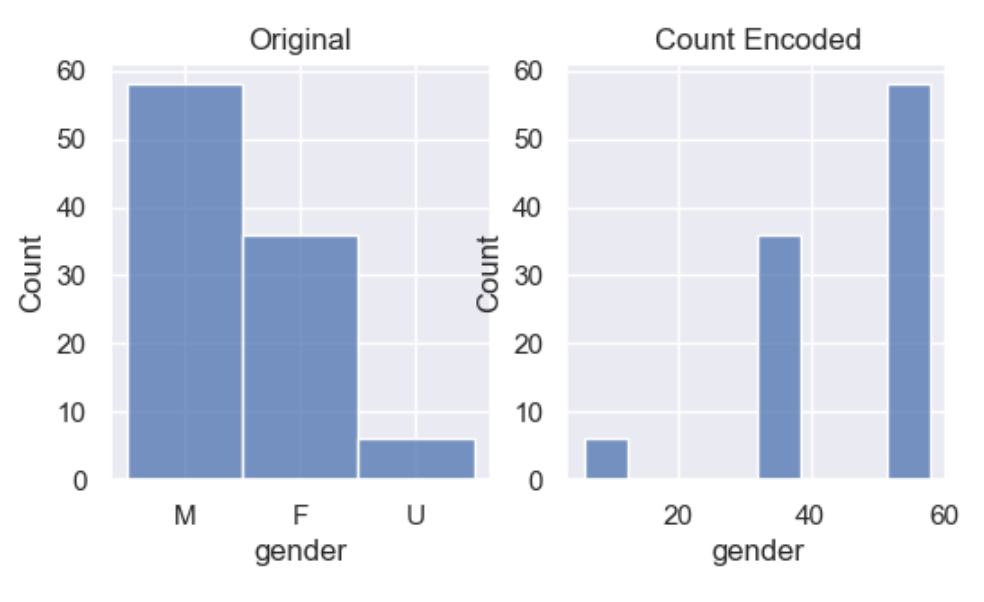
We start with count encoding where by we replace the categories by the count of the observations for that category. The assumption of this technique is that the number observations shown by each variable is somewhat informative of the predictive power of the category. The obvious danger is if 2 different categories appear the same amount of times in the dataset.
df_encoded = wr.tools.model_encode_count(df, headers=['gender', 'code'])
Integer encoding replaces the categories by digits from 1 to n, where n is the number of distinct categories of the variable. Integer encoding can be either nominal or orinal.
Nominal data is categorical variables without any particular order between categories. This means that the categories cannot be sorted and there is no natural order between them.
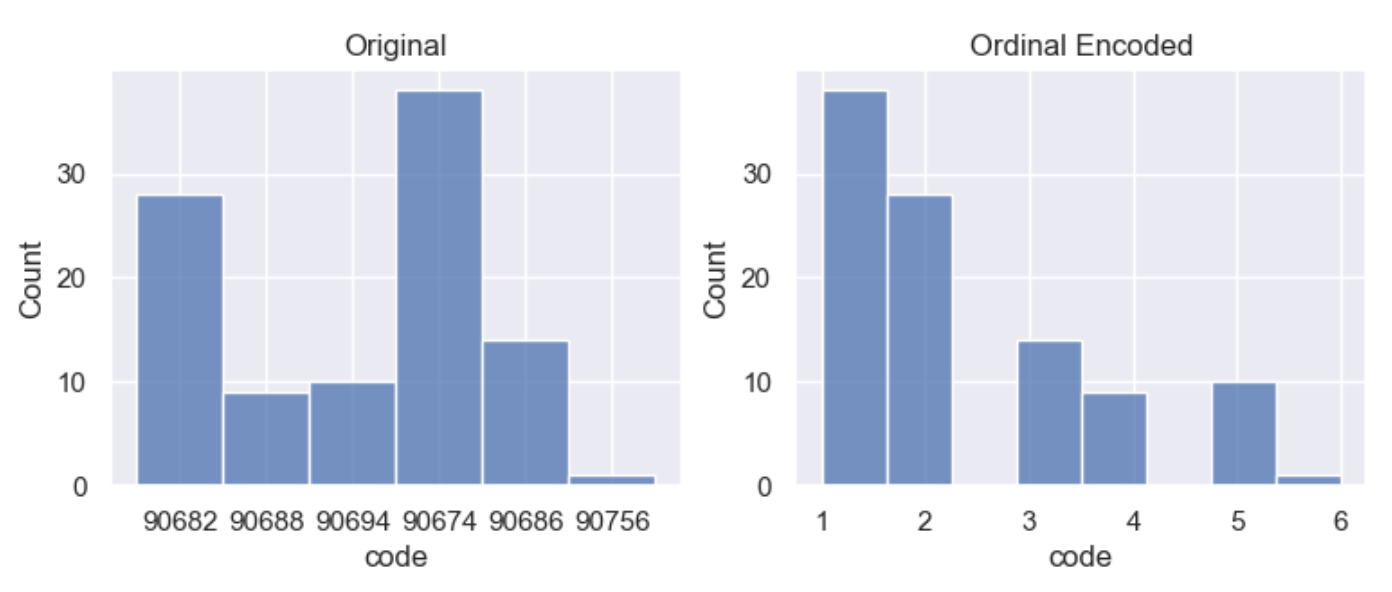
Ordinal data represents categories with a natural, ordered relationship between each category. This means that the categories can be sorted in either ascending or descending order. In order to encode integers as ordinal, a ranking must be provided.
df_encoded = wr.tools.model_encode_integer(df, headers=['code'], ranking=['90674', '90682', '90686', '90694', '90688', '90756'])
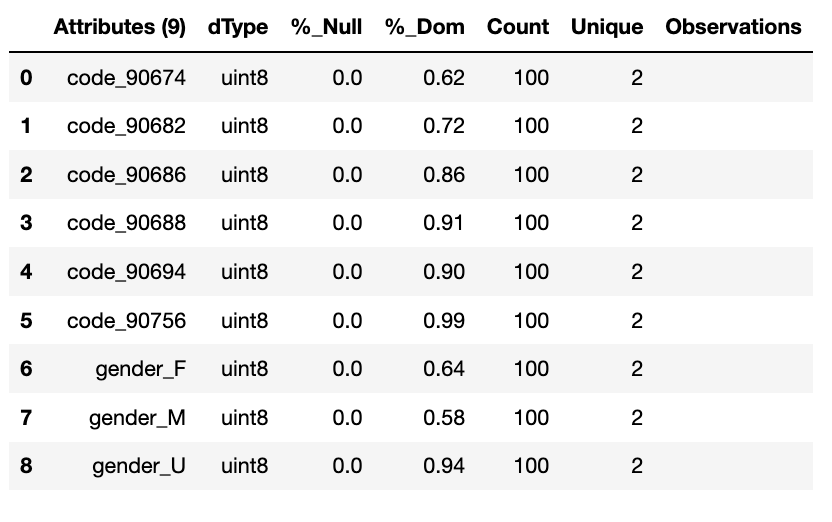
One hot encoding, creates a new column for each categorical variable taking values 0 or 1 indicating if a category is present in an observation. One hot encoding makes data more useful and expressive, and it can be rescaled easily. It provides more nuanced predictions than single labels.
df_encoded = wr.tools.model_encode_one_hot(df, headers=['gender', 'code'])
wr.canonical_report(df_encoded, stylise=False)
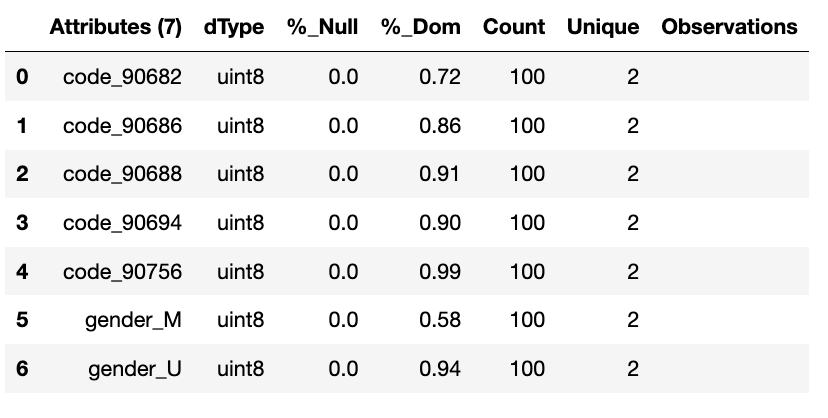
One hot encoding into k-1 binary variables takes into account that we can use 1 less dimension and still represent the whole information. Most machine learning algorithms, consider the entire data set and therefore, encoding categorical variables into k-1 binary variables is better as it avoids introducing redundant information and can reduce bias.
df_encoded = wr.tools.model_encode_one_hot(df, headers=['gender', 'code'], drop_first=True)
wr.canonical_report(df_encoded, stylise=False)
Discretisation
Discretisation is the process of transforming continuous variables into discrete variables by creating a set of contiguous intervals that span the range of the variable’s values. Discretisation helps handle outliers by placing these values into the lower or higher intervals, together with the remaining values of the distribution. Thus, these outlier observations no longer differ from the rest of the values at the tails of the distribution, as they are now all together in the same interval. In addition, by creating appropriate intervals, discretisation can help spread the values of a skewed variable across a set of intervals with an equal number of observations.
sample_size = 100
df = pd.DataFrame(index=range(sample_size))
df['num'] = builder.tools.get_distribution(distribution='lognormal', size=sample_size, seed=11, mean=0, sigma=1)
Setting granularity as an integer evenly creates that number of
intervals
df['cat'] = wr.tools.correlate_discrete_intervals(df, header='num', granularity=6)
0.147->1.38333 55
1.38333->2.61967 31
2.61967->3.856 7
3.856->5.09233 5
5.09233->6.32867 1
6.32867->7.565 1
Setting granularity as a float indicates the gap between each
interval
df['cat'] = wr.tools.correlate_discrete_intervals(df, header='num', granularity=1.0)
0.147->1.147 52
1.147->2.147 28
2.147->3.147 9
3.147->4.147 6
4.147->5.147 3
5.147->6.147 1
Setting granularity as a list gives the percentile or quantities,
All should fall between 0 an 1
df['cat'] = wr.tools.correlate_discrete_intervals(df, header='num', granularity=[0.1,0.25,0.5,0.75,0.9])
0.55125->1.036 25
1.036->1.9045 25
1.9045->3.4143 15
0.2694->0.55125 15
3.4143->7.565 10
0.147->0.2694 10
Setting granularity as a list of tuples gives us domain knowledge
discretisation where the user provides specific interval periods.
df['cat'] = wr.tools.correlate_discrete_intervals(df, header='num', granularity=[(0,0.2),(0.2,0.7),(0.7,2),(2,3),(3,8)])
0.7->2 45
0.2->0.7 27
3->8 12
2->3 11
0->0.2 5
With the intervals created we are also able to rename the new features appropriate for their use. In this case we are creating three even bins and naming them low, medium and high.
df['cat'] = wr.tools.correlate_discrete_intervals(df, header='num', granularity=3, categories=['low', 'mid', 'high'])
low 86
mid 12
high 2
Outlier capping or removal
An outlier is a data point which is significantly different from the remaining data. Statistics such as the mean and variance are very susceptible to outliers. In addition, some machine learning models are sensitive to outliers which may decrease their performance.
Note we have have already seen discretisation used as a means of outlier capping.
# create a dataset with outliers
sample_size = 100
df = pd.DataFrame(index=range(sample_size))
df['num'] = builder.tools.get_dist_bounded_normal(mean=0, std=0.3, upper=1, lower=-1, size=sample_size, seed=11)
df['num'].iloc[:4] = [1.2, 1.03, 1.12, -1.04]
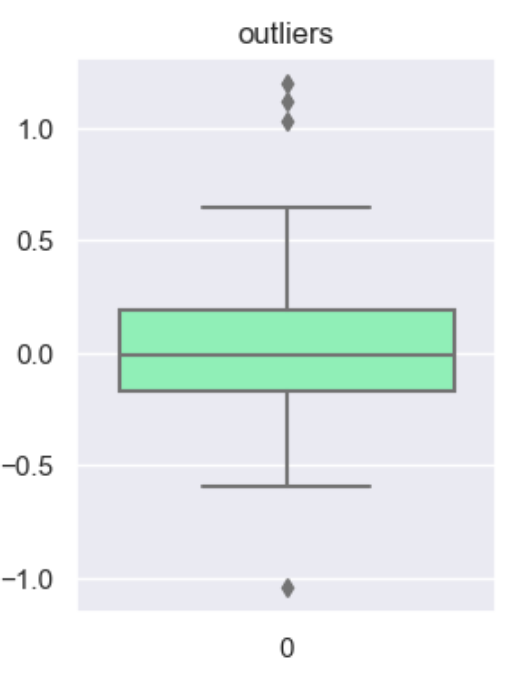
This technique creates a column that marks outliers with a 1 if identified or a 0 if not. This allows us to create a broader set of options to deal with outlier variables.
df['outliers'] = wr.tools.correlate_mark_outliers(df, header='num')
0 96
1 4
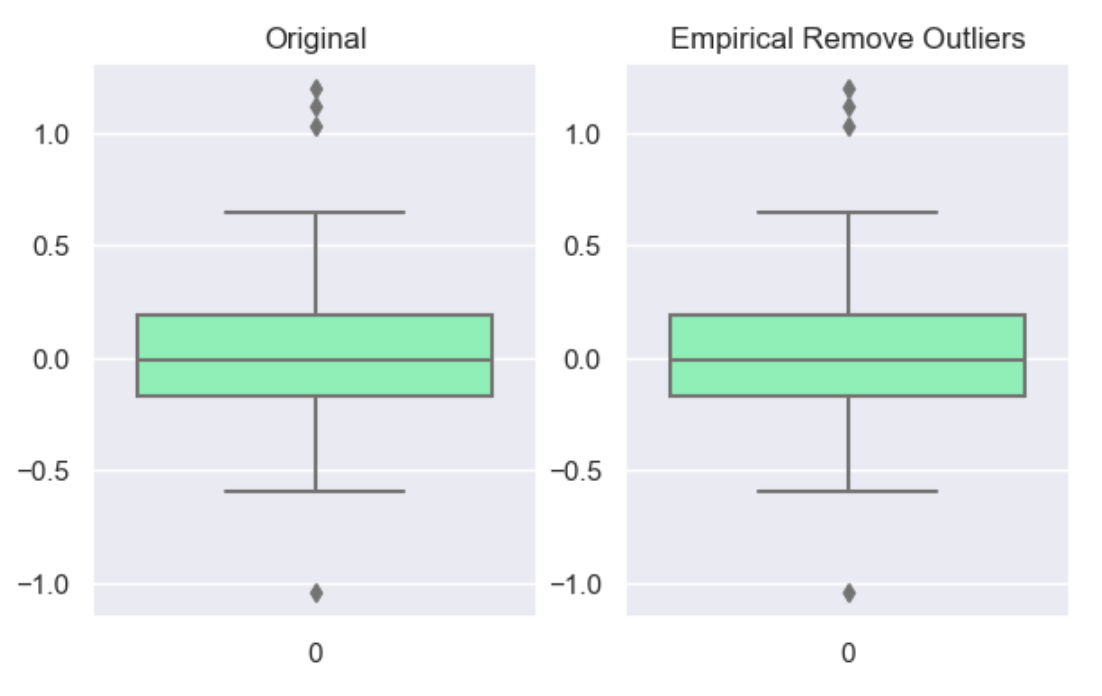
The ‘empirical’ rule states that for a normal distribution, nearly all of the data will fall within three standard deviations of the mean. Given mu and sigma, a simple way to identify outliers is to compute a z-score for every value, which is defined as the number of standard deviations away a value is from the mean. therefor measure given should be the z-score or the number of standard deviations away a value is from the mean. The 68–95–99.7 rule, guide the percentage of values that lie within a band around the mean in a normal distribution with a width of two, four and six standard deviations, respectively and thus the choice of z-score
df_cap = wr.tools.model_drop_outliers(df, header='num', method='empirical', measure=4)
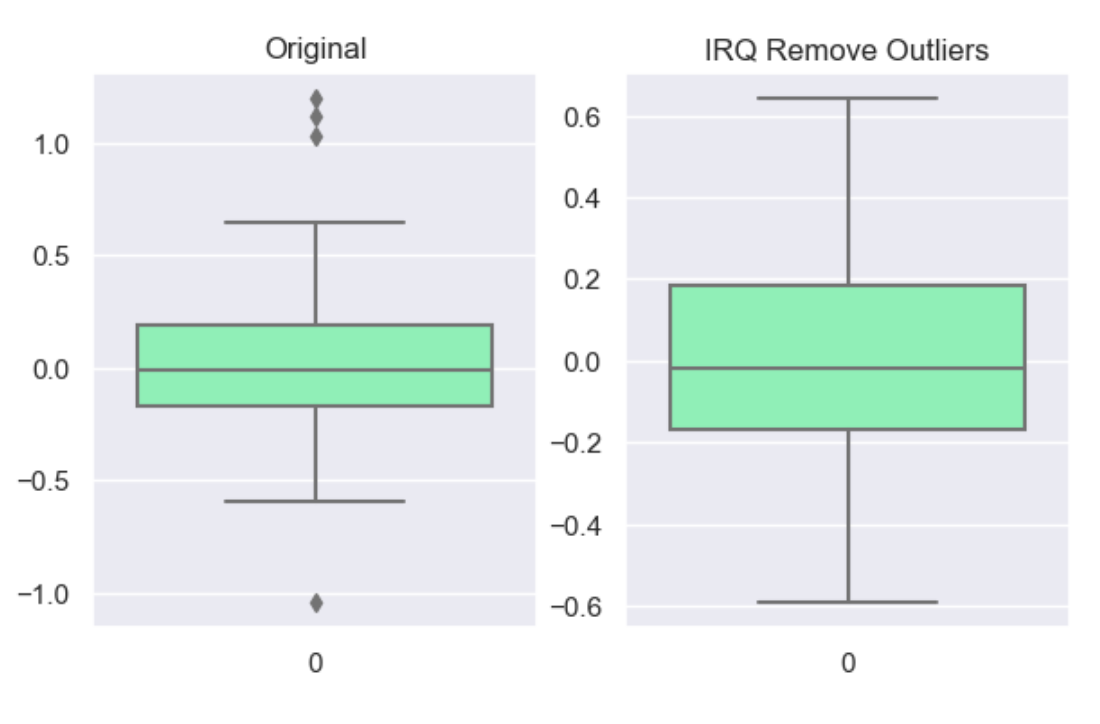
For the ‘interquartile’ range (IQR), also called the midspread, middle 50%, or H‑spread, is a measure of statistical dispersion, being equal to the difference between 75th and 25th percentiles, or between upper and lower quartiles of a sample set. The IQR can be used to identify outliers by defining limits on the sample values that are a factor k of the IQR below the 25th percentile or above the 75th percentile. The common value for the factor k is 1.5. A factor k of 3 or more can be used to identify values that are extreme outliers.
df_cap = wr.tools.model_drop_outliers(df, header='num', method='interquartile', measure=3)
Feature Scaling
Feature scaling refers to the methods or techniques used to normalize the range of independent variables in our data, or in other words, the methods to set the feature value range within a similar scale. Feature scaling is generally the last step in the data preprocessing pipeline, performed just before training the machine learning algorithms.
Feature magnitude matters because: * The regression coefficients of linear models are directly influenced by the scale of the variable. * Gradient descent converges faster when features are on similar scales * Feature scaling helps decrease the time to find support vectors for SVMs * Euclidean distances are sensitive to feature magnitude. * Some algorithms, like PCA require the features to be centered at 0.
sample_size = 100
df = pd.DataFrame(index=range(sample_size))
df['dist'] = builder.tools.get_dist_normal(mean=10, std=3, size=sample_size, seed=11)
print(f"mean: {np.around(df['dist'].mean())}, std {np.around(df['dist'].std())}, min {np.around(df['dist'].min())}, max {np.around(df['dist'].max())}")
mean: 10.0, std 3.0, min 4.0, max 16.0
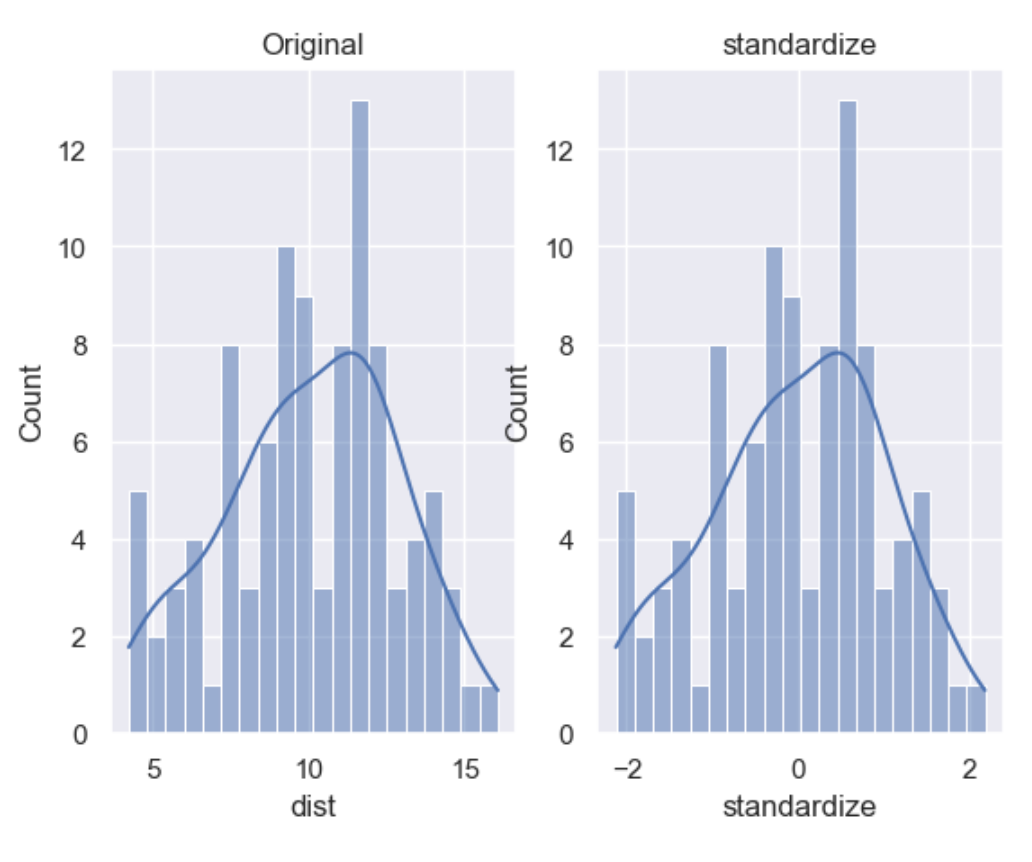
Standardisation involves centering the variable at zero, and standardising the variance to 1. The procedure involves subtracting the mean of each observation and then dividing by the standard deviation.
where \(s\) is the standard deviation of \(x\), and \(s\)
\(s\) = sample standard deviation
\(\sum\) = sum of…
\(X\) = each value
\(\bar{x}\) = sample mean
\(n\) = number of values in the sample
The result of the above transformation is z, which is called the z-score, and represents how many standard deviations a given observation deviates from the mean. A z-score specifies the location of the observation within a distribution (in numbers of standard deviations respect to the mean of the distribution). The sign of the z-score (+ or - ) indicates whether the observation is above (+) or below ( - ) the mean.
The shape of a standardised (or z-scored normalised) distribution will be identical to the original distribution of the variable. If the original distribution is normal, then the standardised distribution will be normal. But, if the original distribution is skewed, then the standardised distribution of the variable will also be skewed. In other words, standardising a variable does not normalize the distribution of the data
df['standardize'] = wr.tools.correlate_numbers(df, header='dist', standardize=True)
Normalization is a data preparation technique that is frequently used. Normalisation involves centering the variable at zero, and re-scaling a given value range. The procedure involves subtracting the mean of each observation and then dividing it by difference between the minimum and maximum value.
The result of the above transformation is a distribution that is centered at 0, and its minimum and maximum values are within the range of -1 to 1. The shape of a mean normalised distribution will be very similar to the original distribution of the variable, but the variance may change, so not identical.
df['normalize'] = wr.tools.correlate_numbers(df, header='dist', normalize=(-1,1))
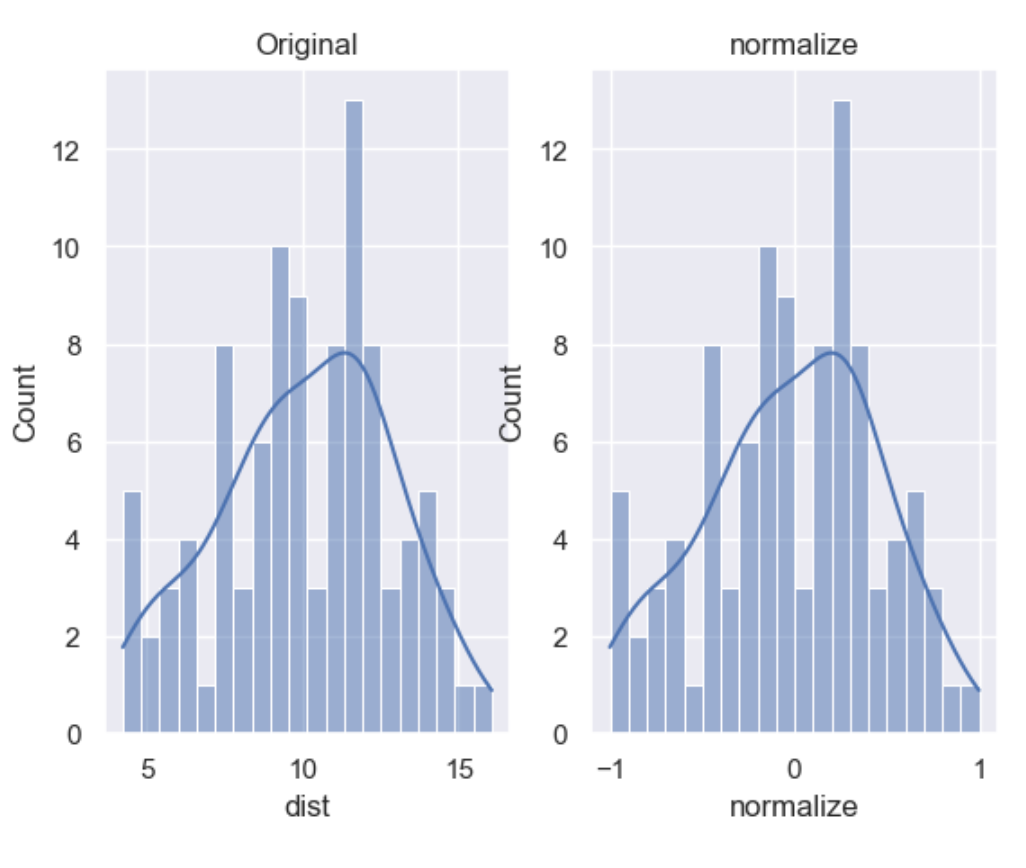
Variable transformation
Some machine learning models like linear and logistic regression assume that the variables are normally distributed. Often, variables are not normally distributed, but, transforming the variables to map their distribution to a Gaussian distribution may, and often does, boost the performance of the machine learning algorithm.The most commonly used
sample_size = 100
df = pd.DataFrame(index=range(sample_size))
df['dist'] = builder.tools.get_distribution(distribution='beta', size=sample_size, seed=11, a=1, b=5)
The most commonly used methods to transform variables are:
Logarithmic transformation - \(\log(x)\)
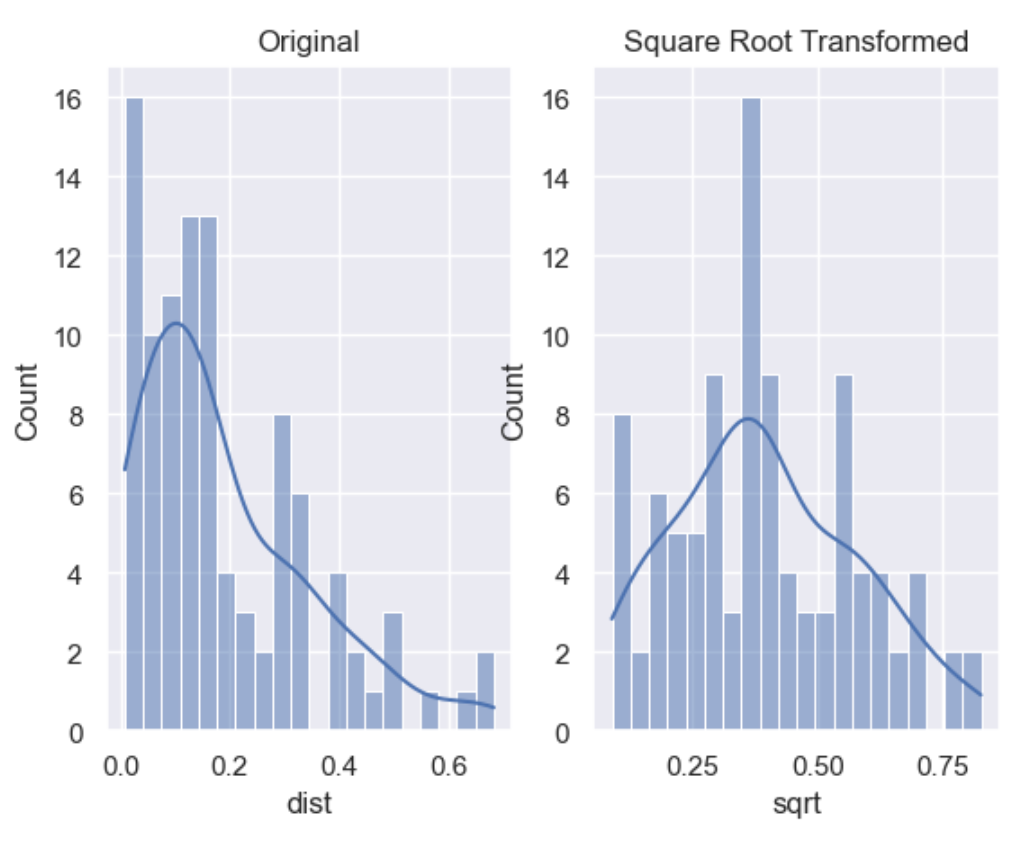
Square root transformation - \(\sqrt x\)
Qube root transformation - \(\sqrt[3]{x}\)
In our example we show the transformation parameter set to sqrt
but can be set to log or cbrt
df['sqrt'] = wr.tools.correlate_numbers(df, header='dist', transform='sqrt')
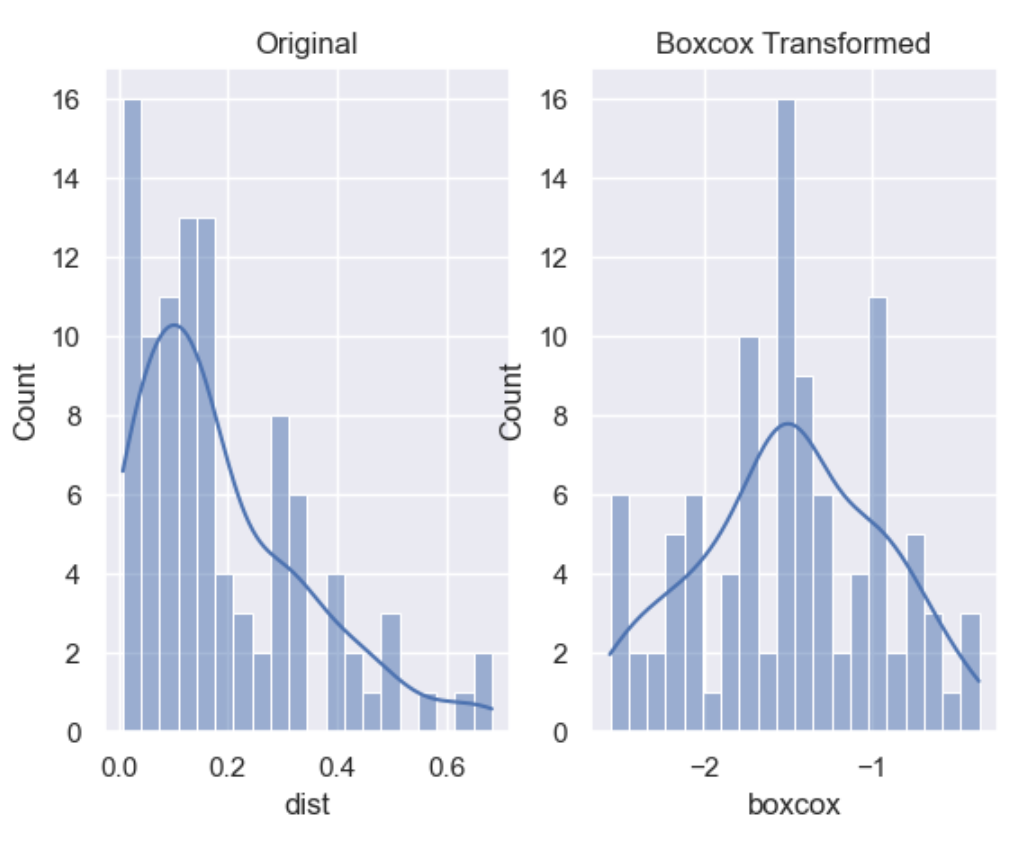
The Box-Cox transformation is an adaptation of the exponential transformation, scanning through various exponents, and it already represents the untransformed variable, as well as the log transformed, reciprocal, square and cube root transformed, as the lambda varies across the range of -5 to 5. So by doing Box-Cox transformation, in a way, we are evaluating all the other transformations and choosing the best one. Box-Cox can only be applied to positive variables.
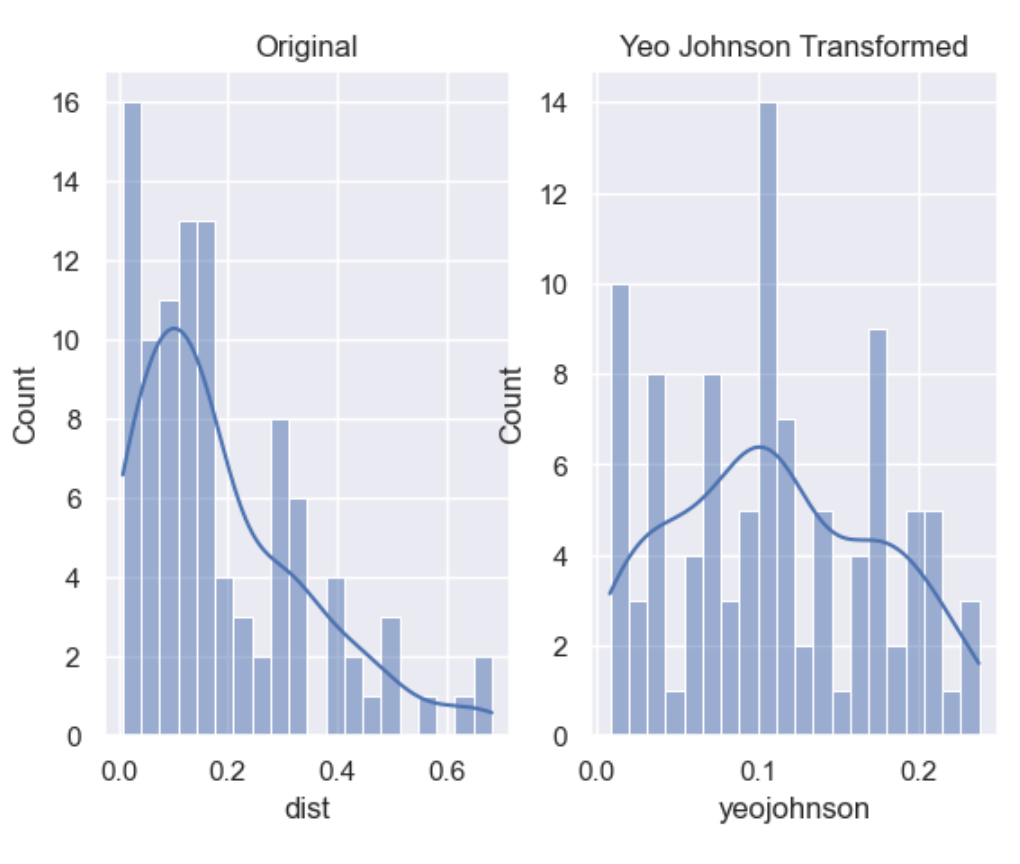
df['boxcox'] = wr.tools.correlate_numbers(df, header='dist', transform='boxcox')
Yeo-Johnson is a modification of the Box-Cox transformation so that it can be applied as well to non-positive variables
df['yeojohnson'] = wr.tools.correlate_numbers(df, header='dist', transform='yeojohnson')