Project Hadron
Introduction
Project Hadron addresses feature engineering, data preprocessing, synthetic data, model predict, and other rapidly growing artificial intelligence (AI) and machine learning (ML) use cases. It directly focuses on data science capabilities and the execution of those capabilities as component microservice. It is built using object-oriented design (OOD) and object-oriented programming (OOP) to provide an extendable framework for quick build component solutions.
Project Hadron has been built to bridge the gap between data scientists and data engineers. More specifically between machine learning business outcomes or use case and a product pipeline. It translates the work of data scientists into meaningful, production ready solutions that can be easily integrated into a DevOps, CI/CD pipeline.
Project Hadron provides a clear separation of concerns, whilst maintaining the original intentions of the data scientist, that can be passed to a production team. It offers trust in the form of expected delivery and no code integration between the data scientists teams and product teams. It brings with it transparency and traceability, dealing with bias, fairness, and knowledge and presents data profiling and data legacy. The resulting outcome provides DevOps with adaptability, robustness, and reuse, fitting seamlessly into a microservices architecture.
Project Hadron is designed using Microservices. Microservices is an architectural style for building software applications as a collection of small, independently deployable services that work together to provide a specific functionality. Each microservice is designed to be modular, lightweight, and scalable, and can be developed, deployed, and maintained independently of the other services.
Microservices offer many advantages such as:
Highly maintainable and testable
Loosely coupled
Independently deployable
Highly reusable
Resilient
Technically independent
Microservices are typically organized around specific business capabilities and each service performs a single function. Because they are independently run, each service can be updated, deployed, and scaled to meet demand for specific functions of an application. Project Hadron microservices enable the rapid, frequent and reliable delivery of large, complex applications. It also enables an organization to evolve its data science stack and experiment with innovative ideas.
Main features
Data Preparation
Feature Selection
Feature Engineering
Feature Cataloguing
Model Prediction
Custom Build
Augmented Knowledge
Synthetic Data Modelling
Data Reporting
Data Lineage
Data Profiling
Data Traceability
Data lineage refers to the data’s journey from its origin through its various transformations, storage locations, and usage. It is a detailed record of the data’s origin, how it has been transformed or processed, and where it has been stored or moved over time. Data lineage helps organizations understand the data’s history, quality, and reliability, which are critical factors for compliance, auditing, and decision-making purposes. It provides insights into data sources, transformations, and dependencies that enable organizations to track data’s flow and lineage, understand its impact on various business processes, and ensure its accuracy, consistency, and security.
Data profiling is the process of analyzing and examining data from various sources to understand its structure, content, quality, and completeness. It involves collecting descriptive statistics and metadata to gain insights into data elements, such as data types, length, format, patterns, and relationships. Data profiling helps organizations identify potential issues with their data, such as missing orin consistent values, duplicates, outliers, and data quality problems. By analyzing data profiles, organizations can gain a better understanding of their data, detect data quality issues, and take corrective actions to improve data accuracy, completeness, and consistency. Data profiling can be used in a variety of contexts, including data migration, data integration, data warehousing, and data governance. It is a crucial step in the data preparation process, which helps organizations ensure that their data is reliable, consistent, and of high quality.
Data traceability is the ability to track and follow the flow of data from its source to its destination, including all the transformations and processing it undergoes. It is a critical aspect of data governance, compliance, and risk management, as it enables organizations to understand where their data comes from, how it has been processed, and where it has been used.
All together they are a critical component of modern data management practices, especially in industries such as healthcare, finance, and government, where data privacy and security are essential.
Component capabilities
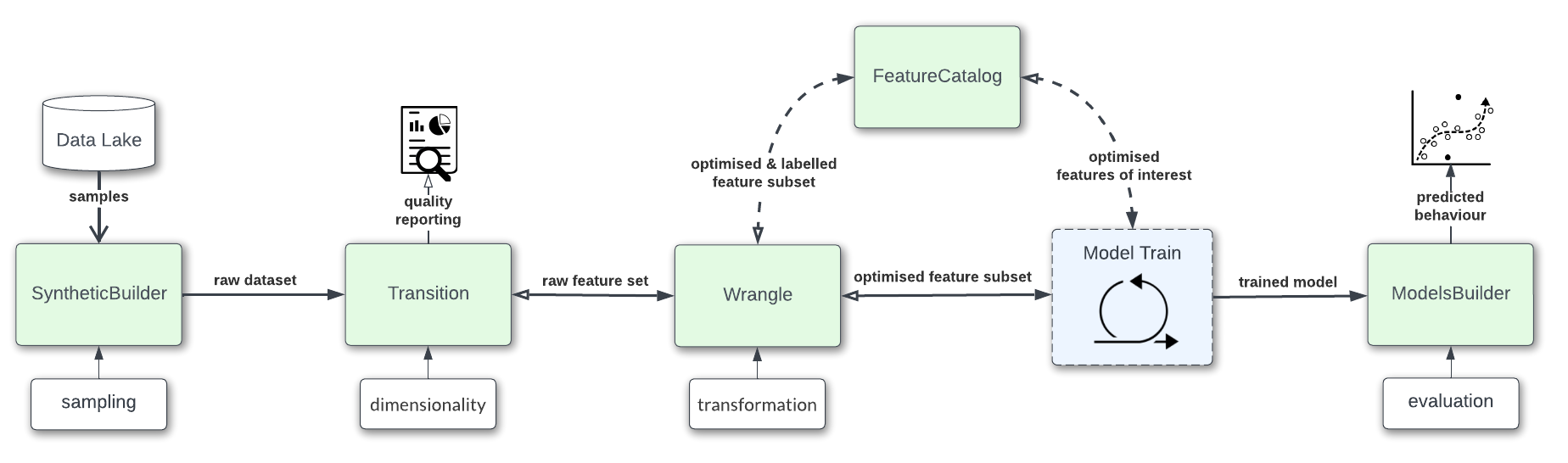
The Project Hadron package comes with a number of component capabilities some of which are listed below as the component name. Each capability represents a separation of concerns across the stakeholders and data science teams model build workflow.
SyntheticBuild - Synthetic data through Sampling, Subject Matter Expertise, artifacts and insight
Transition - Selection through dimensionality reduction
Wrangle - Feature Engineering through variable transformation
FeatureCatalog - Feature cataloging through label optimisation
ModelsBuilder - Model predict once the algorithm is trained and optimised
The diagram illustrates a typical workflow for stakeholders and data science teams looking to implement business objectives. Highlighted within the diagram are where the capability components sit within the workflow.
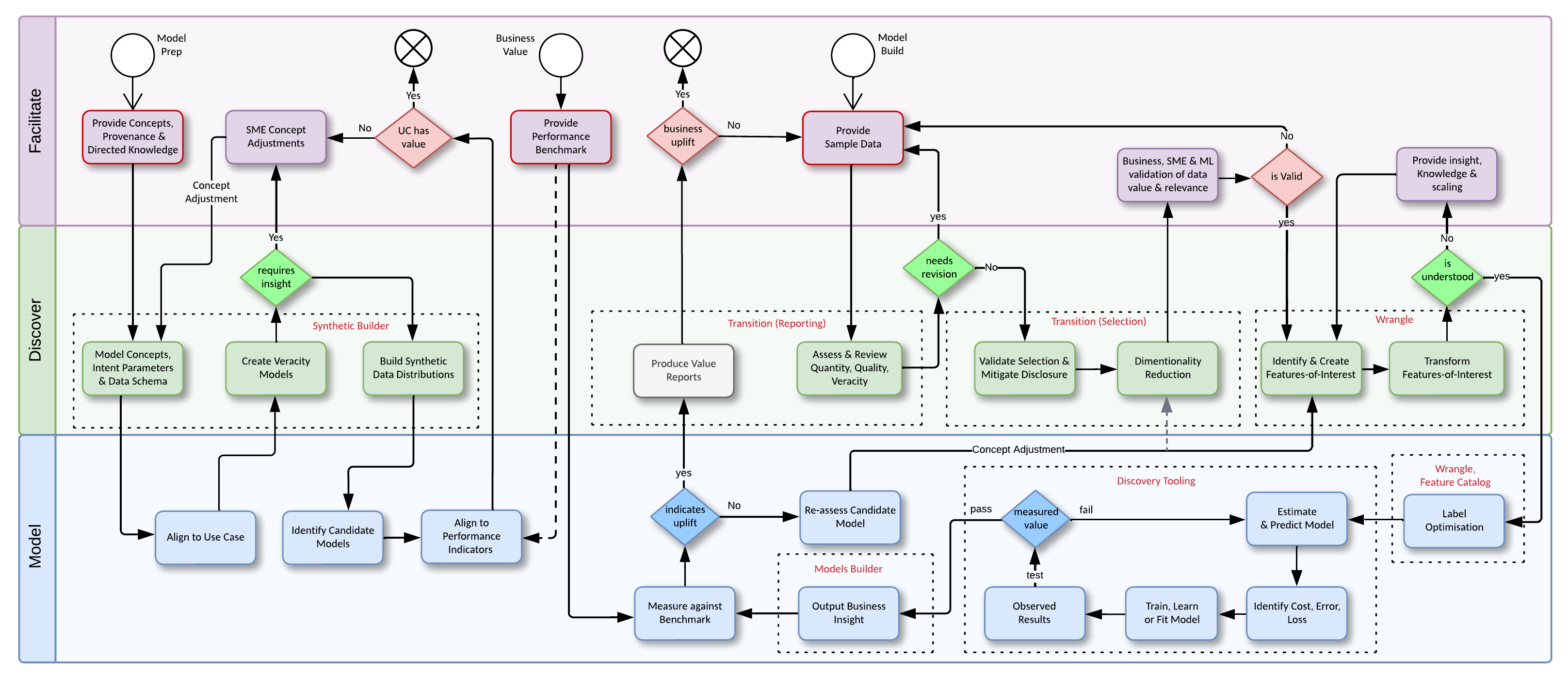
The rectangles with a dotted outline box, that surround the processes, represent the components used at that point within the workflow. Found within the rectangle is the name of the component used and in brackets its use. This may not fit every workflow but when building a model, be it for production or as a proof of concept, each of these capabilities are at the core of any model build and allow bridging the gap between data science and production engineering.-
Feature transformers
Project Hadron is a Python library with multiple transformers to engineer and select features to use across a synthetic build, statistics and machine learning.
Missing data imputation
Categorical encoding
Variable Discretization
Outlier capping or removal
Numerical transformation
Redundant feature removal
Synthetic variables creation
Synthetic variables engineer
Datetime features
Time series
Project Hadron allows one to present optimal parameters associated with each transformer, allowing different engineering procedures to be applied to different variables and feature subsets.
Background
Born out of the frustration of time constraints and the inability to show business value within a business expectation, this project aims to provide a set of tools to quickly build production ready data science disciplines within a component based solution demonstrating coupling and cohesion between each disipline, providing a separation of concerns between components.
It also aims to improve the communication outputs needed by ML delivery to talk to Pre-Sales, Stakeholders, Business SME’s, Data SME’s product coders and tooling engineers while still remaining within familiar code paradigms.