Introducing Components
Project Hadron is designed using Microservices. Microservices are an architectural patterns that structures an application as a collection of component services.
Component services are built for business capabilities and each service performs a single function. Because they are independently run, each component can be updated, deployed, and scaled to meet demands for specific functions of an application. Component services provide a separation of concerns that are weakly coupled and highly cohesive increasing code quality and developer productivity.
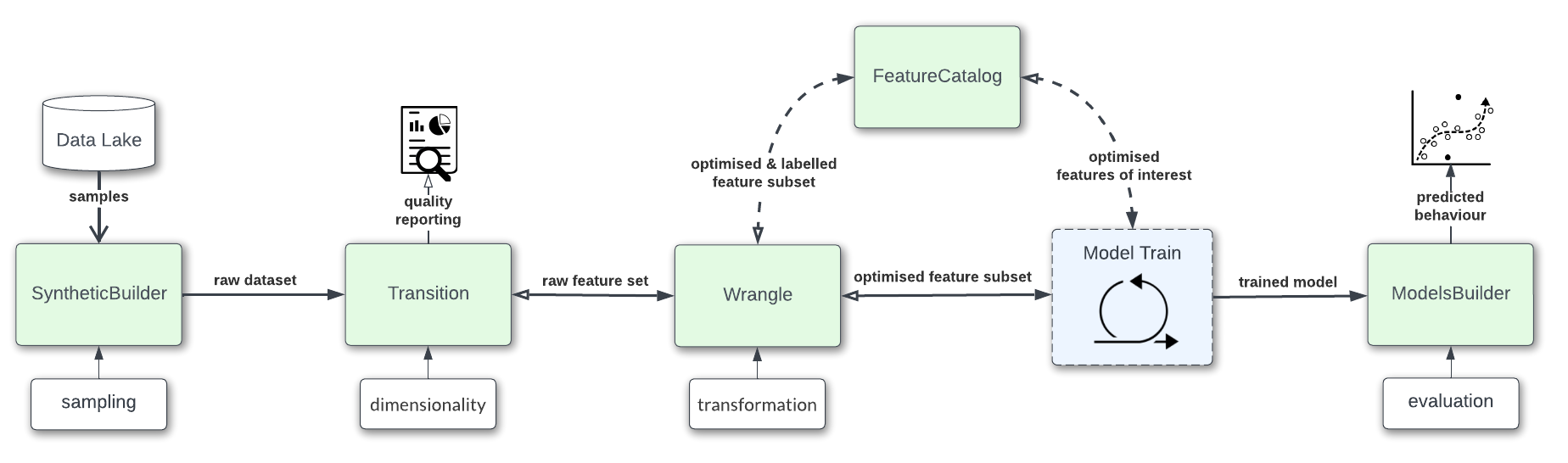
This tutorial shows the fundamentals of how to run a basic Project Hadron component. It is the simplest form of running a task demonstrating the input, throughput and output of a dataset. Each instance of the component is given a unique reference name whereby the component uses that name as its unique identifier and thus can be used to reference the said component for the purposes of referencing and reloading.
First Steps
Firstly we have imported a component from the Project Hadron library for this demonstration. It should be noted, the choice of component is arbitrary for this demonstration, as even though each component has its own unique set of tasks it also has methods shared across all components. In this demonstration we only use these common tasks, this is why the choice of component is arbitrary.
from ds_discovery import Transition
To create a named component we have used the Factory method from_env
and given it a referencable name hello_comp, and as this is the first
instantiation, we have used the one off parameter call has_contract that
by default is set to True and is used to avoid the accidental loading of a
component instance of the same task name. As common practice we capture the
instance of this specific component transition as tr.
tr = Transition.from_env('hello_comp', has_contract=False)
We have set where the data is coming from and where the resulting data is going to. The source identifies a URI (URL) from which the data will be collected and in this case persistence uses the default settings, more on this later.
tr.set_source_uri('https://www.openml.org/data/get_csv/16826755/phpMYEkMl.csv')
tr.set_persist()
Run Component
To run a component we use the common method run_component_pipeline
which loads the source data, executes the component task then persists
the results. This is the only method you can use to run the tasks of a
component and produce its results and should be a familiarized method.
tr.run_component_pipeline()
This concludes building a component and though the component doesn’t change the throughput, it shows the core steps to building any component.
Reloading and Extending the Component
Though this is a single notebook, one of the powers of Project Hadron is
the ability to reload component state across new notebooks, not just
locally but even across locations and teams. To load the component state
we use the same factory method from_env passing the unique component
name hello_comp which reloads the named component. We have now
reinstated the original component state and can continue to work on
this component.
tr = Transition.from_env('hello_comp')
Lets look at a sample of some commonly used features that allow us to peek inside the components. These features are extremely useful to navigate the component and should become familiar.
The first and probably most useful method call is to be able to retrieve
the results of run_component_pipeline. We do this using the
component method load_persist_canonical. Because of the retained
state the component already knows the location of the results, and in
this instance returns a report.
Note: All the components from a package internally work with a canonical data set. With this package of components, because they are data science based, use Pandas Dataframes as their canonical, therefore wherever you see the word canonical this will relate to a Pandas Dataframe.
df = tr.load_persist_canonical()
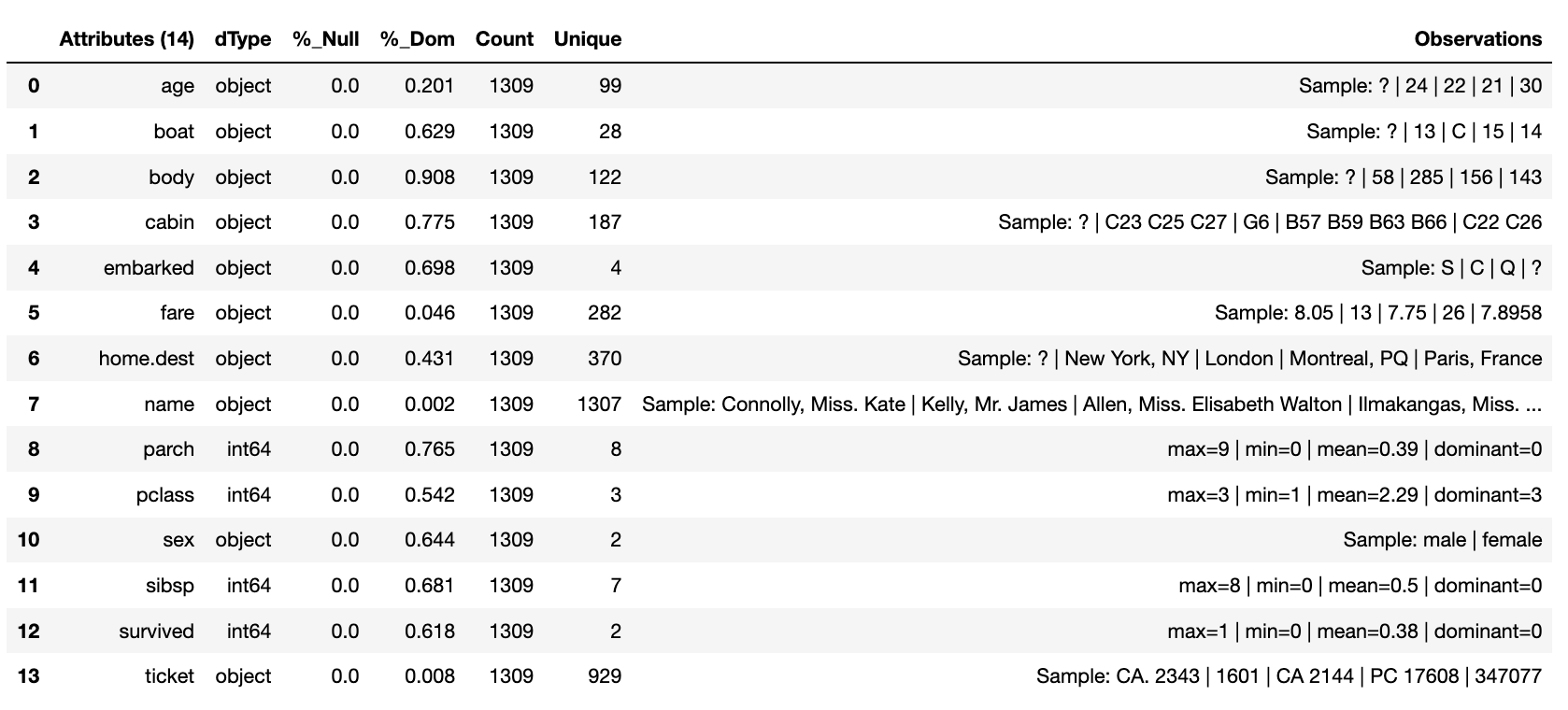
The second most used feature is the reporting tool for the canonical. It allows us to look at the results of the run as an informative dictionary, this gives a deeper insight into the canonical results. Though unlike other reports it requests the canonical of interest, this means it can be used on a wider trajectory of circumstances such as looking at source or other data that is being injested by the task.
Below we have an example of the processed canonical where we can see the results of the pipeline that was persisted. The report has a wealth of information and is worth taking time to explore as it is likely to speed up your data discovery and the understanding of the dataset.
tr.canonical_report(df)
When we set up the source and persist we use something called Connector contracts, these act like brokers between external data and the internal canonical. These are powerful tools that we will talk more about in a dedicated tutorial but for now consider them as the means to talk data to different data storage solutions. In this instance we are only using a local connection and thus a Connector contract that manages this type of connectivity.
In order to report on where the source and persist are located, along
with any other data we have connected to, we can use
report_connectors which gives us, in part, the name of the connector
and the location of the data.
tr.report_connectors()

This gives a flavour of the tools available to look inside a component and time should be taken viewing the different reports a component offers.
Environment Variables
To this point we have been using the default settings of where to store the named contract and the persisted dataset. These are in general local and within your working directory. The use of environment variables frees us up to use an extensive list of connector contracts to store the data to a location of choice.
Hadron provides an extensive list of environment variables to tailor how your components retrieve and persist their information, this is beyond the scope of this tutorial and tends to be for specialist use, therefore we are going to focus on the two most commonly used for the majority of projects.
We initially import Python’s os package.
import os
In general and as good practice, most notebooks would run a set up
file that contains imports and environment variables that are common
across all notebooks. In this case, for visibility, because this is a
tutorial, we will import the packages and set up the two environment
variables within each notebook.
The first environment variable we set up is for the location of the Domain Contract. Domain Contracts are the outcome of named component instances and collect together metadata that are pertinent to the specific component tasks and actions. Domain Contracts are critical references of the components and other components that rely on them.
From this point on we use the name ‘Domain Contract’ to represent the outcome of the named component instance which constitute the components task and used to run the component.
In this case we are setting the Domain Contract location to be in a common local directory of our naming.
os.environ['HADRON_PM_PATH'] = '0_hello_meta/demo/contracts'
The second environment variable is for the location of where the data is to be persisted. This allows us to place data away from the working files and have a common directory where data can be sourced or persisted. This is also used internally within the component to avoid having to remember where data is located.
os.environ['HADRON_DEFAULT_PATH'] = '0_hello_meta/demo/data'
As a tip we can see where the default path environment variable is set
by using report_connectors. By passing the parameter
inc_template=True to the report_connectors method, showing us
the connector names. By each name is the location path (uri) where, by
default, the component will source or persist the data set, this is
taken from the environment variable set. Likewise we can see where the
Domain Contract is being persisted by including the parameter inc_pm
giving the location path (uri) given by the environment variable.
tr.report_connectors(inc_template=True)

Because we have now changed the location of where the Domain Contract can be found we need to reset things from the start giving the source location and using the default persist location which we now know has been set by the environment variable.
tr = Transition.from_env('hello_tr,', has_contract=False)
tr.set_source_uri('https://www.openml.org/data/get_csv/16826755/phpMYEkMl.csv')
tr.set_persist()
Finally we run the pipeline with the new environment variables in place and check everything runs okay.
tr.run_component_pipeline()
And we are there! We now know how to build a component and set its environment variables. The next step is to build a real pipeline and join that with other pipelines to construct the complete master Domain Contract.