Use Case : Synthetic Profile
Synthetic Builder is another example of a Project Hadron capability, having seen selection and feature engineering in our previous examples. Synthetic Builder uses a combination of rules-based actions, defined by subject matter experts along with machine learning libraries and techniques, to define a set of statistically and distributed representative datasets.
In this example we demonstrate the basics of a common use case of customer account details showing quick wins through the tooling when building this type of synthetic dataset.
Project Hadron Canonicalizes data following the canonical model pattern so that every component speaks the same data language. In this case and with this package all components use Pandas DataFrame format. This is common format used by data scientists and statisticians to manipulate and visualise large datasets.
Before we do that, and as shown in the previous section, we now use the environment variables to define the location of the Domain Contract and datastore.
import os
os.environ['HADRON_PM_PATH'] = '0_hello_meta/synthetic/contracts'
os.environ['HADRON_DEFAULT_PATH'] = '0_hello_meta/synthetic/data'
Setting Up
We initially load Project Hadron’s Synthetic Builder instance that provides us access to its capabilities. It is worth noting, synthetic Builder shares some of its actions (Intent) with the feature engineering capability adding additional actions (Intent) to generate the initial data or feature distribution.
Notice we are creating a new component and as such must set up the output of the component. With synthetic build, though it can be defined, there is no concept of a synthetic source as synthetic data in its on right creates that source dataset.
from ds_discovery import SyntheticBuilder
# get the instance
builder = SyntheticBuilder.from_env('hello_builder', has_contract=False)
builder.set_persist()
Building a Distribution
This new component works in exactly the same way as the other components demonstrated earlier, whereby we create the instance pertinent to our intentions and where to persist the results. Then we add the component actions (intent), which in this case is to generate the features we have built and make them appropriate for a machine learning model or for other uses.
As seen before in order to get a list of a component’s actions (intent),
in this case synthetic builder, you can use the Python method
__dir__(). Remember this method call can be used in any component.
As we do not have a source we first need to define our DataFrame that the data will fit into and for convenience we create a variable for the sample size that can be applied to all required build methods.
import pandas as pd
sample_size = 1000
df = pd.DataFrame(index=range(sample_size))
Building a profile
We initially need to create the distribution data using the get_
methods. In this case we are using get-numbers to retrieve a random
set of values and using the at_most parameter to specify those
values to be unique.
Next use get_catagory to define language using the
relative_freq parameter to specify the distribution of these
catagories.
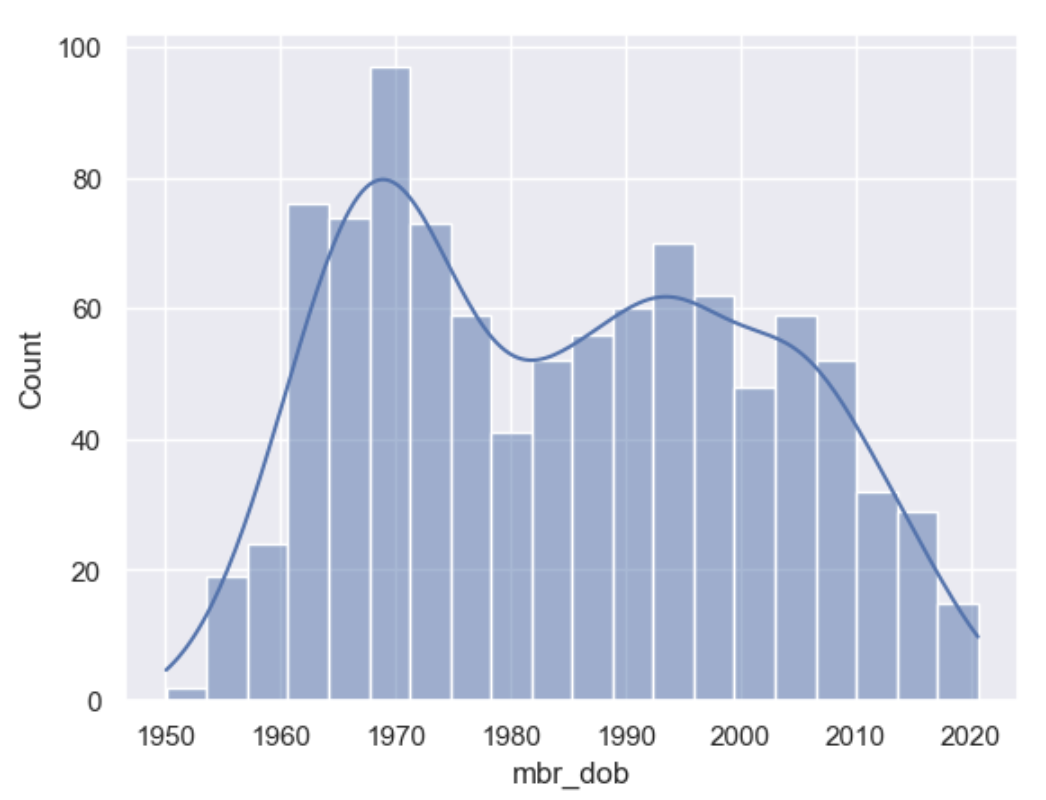
Finally use get_datetime to get a date of birth of the profile based
on current time. We achieve this by using seconds from now, be they
posative or negative, to calculate a datetime. Dates now stay up to date
each run, though real date margins can be used.
df['profile_id'] = builder.tools.get_number(from_value=100000, to_value=999999, at_most=1, size=sample_size, column_name='profile_id')
df['language'] = builder.tools.get_category(selection=['ENGL', 'SPAN', 'CHIN', 'RUSS', 'OTHERS'], relative_freq=[92,6,1,1,.4], size=sample_size, column_name='language')
df['mbr_dob'] = builder.tools.get_datetime(start=-29500, until=-730, relative_freq=[0.001,0.1,1,3,5,3,2,2,4,3,3,2,1], size=sample_size, column_name='mbr_dob')
import seaborn as sns
sns.set()
sns.histplot(df['mbr_dob'], bins=20, kde=True)
Adding Demographics
When creating personas there are a number of sample data methods. Use persona to retrieve names that match gender and email with the ability to bias the gender gap. Use zipcodes to retrieve a rich sample of location data that is correctly biased towards population density. With both these sample methods there are a couple of parameters to filter on the data you want to retrieve, be that columns or rows.
# persona
df = builder.tools.model_sample_map(canonical=df, sample_map='us_persona', female_bias=0.55, column_name='persona', )
# zipcode
df = builder.tools.model_sample_map(canonical=df, sample_map='us_zipcode', column_name='zipcodes')
Adding Preferences
Finally add preferences for now and to use later as we improve the logic. Remember synthetic building is an iterative process that builds up as ones knowledge improves. For an example we may want to add logic to ensure that those without phone numbers cannot be contacted by SMS or telephone call.
# has phone number
df['prf_has_phone'] = builder.tools.get_category(selection=[1, 0], relative_freq=[15,1], size=sample_size, column_name='prf_has_phone')
# communication channel preference
channels = ["MyPortal", "Phone", "Email", "SMS", "SocialMedia"]
df['prf_channel_pref'] = builder.tools.get_category(selection=channels, relative_freq=[4,1,3,2,2], size=sample_size, column_name='prf_channel_pref')
Run Component Pipeline
To run a component we use the common method run_component_pipeline
which loads the source data, executes the component task then persists
the results. This is the only method you can use to run the tasks of a
component and produce its results and should be a familiarized method.
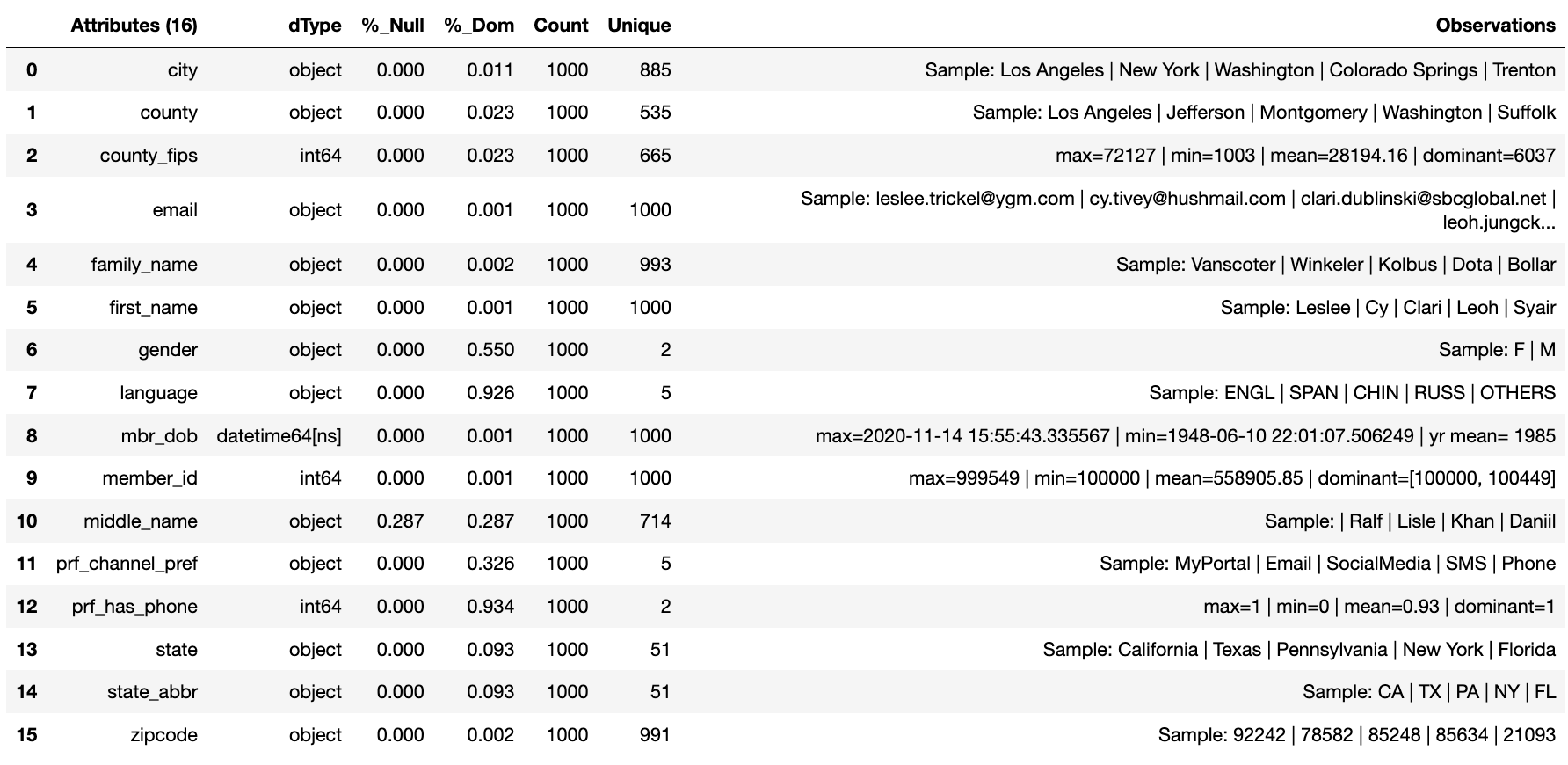
We can now run the run_component_pipeline and use the canonical
report to observe the outcome. From it we can see the columns we have
created, and have been created for us, for the synthetic build.
builder.run_component_pipeline()
builder.canonical_report(builder.load_persist_canonical(), stylise=False)